


Data warehouse gives businesses the ability to consolidate data from various sources, such as transactional systems, operational databases, and flat files. Through data integration, bad data removal, duplication elimination, and standardization to a single source of truth, data warehousing is achieved.
Users can further effectively access and utilize all of the company's data when there is a single source of truth for that data. Additionally, by separating database operations from data analytics, data access performance is often enhanced, resulting in more rapid business insights.
What then is a data warehouse?
A data warehouse is a system that combines data from one or more sources into a single, consistent, central data storage to meet diverse data analytics needs.
The use of machine learning and artificial intelligence in data mining, Online analytical processing, or OLAP, which offers quick, adaptable, and dynamic data analysis for business intelligence and decision is supported by data warehouse systems.
Data warehouse concept
1. Entities, Fact and Dimension
- Entities: This represents the technical or business information in the data warehouse, It can also be described as the model that holds the fact and dimension of the data warehouse.
- Fact: The measurements, metrics, or facts from your business process are known as facts. Quarterly sales figures would serve as a measurement for the sales table.
- Dimension: A business process event's framework is provided by dimension. They provide the who, what, and where of a fact. To put it in simple terms, In the sales business process, dimensions would be - Who - Customers Name - Where - Location - What - Product Name.
2. Star and Snowflake schemas
The star and snowflake schema designs are tools for dividing facts and dimensions into distinct tables. The many levels of a hierarchy are further divided into independent tables using snowflake schemas.
snowflake schemas are designed for writes and are frequently used for transactional data warehousing, while star schemas are optimized for reads and are frequently used for constructing data marts. In a star schema, all hierarchical dimensions have been de-normalized.
- Normalization reduces redundancy and data size
The use of normalization benefits both snowflake and star schemas. The term "Normalization decreases redundancy" highlights a crucial benefit that both schemas take advantage of.
When a table is normalized, its data size usually decreases since expensive data types like strings are probably replaced with much smaller integer types. However, you also need to make a new lookup table with the original objects in it to retain the information's content.
The fact table in the star and snowflake schema data models share identical data, further normalization of your dimensions has no impact on the size or content of the fact table, for Small data this might not be a concern, but for huge data—or simply data that is expanding quickly—will inevitably result to normalizing your fact table to at least the minimal degree of a star schema. Your fact table will develop considerably faster than your dimension tables.
Which schema should I use?
No matter which schema you choose, the fact table is where most queries to the dataset are routed. Your dimension tables can be accessed through your fact table. From the standpoint of an analyst, the fundamental practical distinction between the star and snowflake schemas has to do with data querying.
In comparison to a star schema, a snowflake schema can conduct queries less quickly since it requires more joins to access the deeper layers of the hierarchical dimensions. Thus, the simpler star structure is typically preferred by data scientists and analysts.
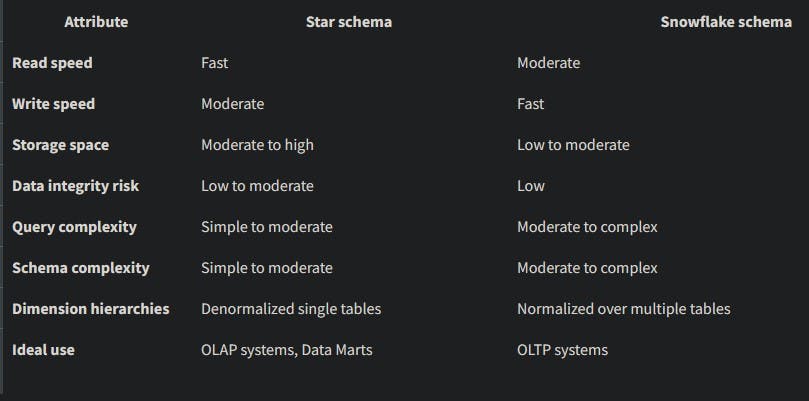
Star schemas work well for data marts or data warehouses that have straightforward fact-dimension relationships, but snowflake schemas are generally preferable for constructing data warehouses, especially those for transaction processing systems.
Consider the situation where point-of-sale records are being accumulated in an OLTP (Online Transaction Processing System) and are being duplicated as part of a daily batch ETL process to one or more OLAP (Online Analytics Processing) systems for further analysis of massive amounts of historical data.
While the OLAP system utilizes a star schema to improve efficiency for frequent reads, the OLTP source may use a snowflake schema to improve efficiency for frequent writes.
Data Warehouse Architecture
A data warehouse architecture is a way to specify the entire design of data processing, communication, and presentation for end-user computing within a company. Despite the differences between each architecture in a data warehouse, they share several essential components in common.
In general, data warehouses feature a three-tier architecture which includes :
Bottom tier: This tier is made up of a data warehouse server, typically a relational database system that gathers, cleanses, and transforms data from various data sources using a procedure called extract, transform, and load (ETL) or extract, load, and transform (ELT).
Middle layer: The middle tier has an OLAP (online analytical processing) server that permits quick query response times. This tier allows for the use of ROLAP, MOLAP, and HOLAP, three different types of OLAP models.
Top tier: The top tier is the front-end user interface or dashboard, which enables end users to perform ad-hoc data analysis on their business data.
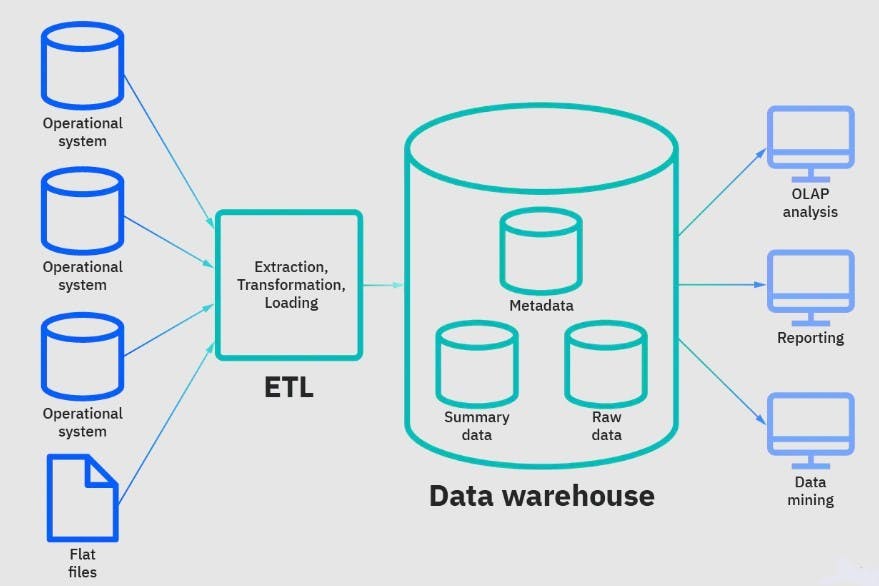 Image 2. Data warehouse architecture Image
Image 2. Data warehouse architecture Image
Applications for data warehouses are made to accommodate user-specific, ad-hoc data requirements, which is now known as online analytical processing (OLAP). These consist of tools including trend analysis, summary reporting, profiling, forecasting, and more.
As OLTP data builds up in production databases, it is routinely removed, filtered, and placed into an accessible warehouse server. It is necessary to de-normalize the tables and clean up any inaccuracies as the warehouse gets filled with data.
List of some well known data warehouse.
Amazon RedShift
Amazon RedShift combines cloud-based, hardware-and software-specific to Amazon Web Services technologies for rapid data encryption, compression, machine learning, and graph optimization algorithms that automatically arrange and store data.
Snowflake
Snowflake provides a multi-cloud analytics solution. Snowflake promotes the constant encryption of both in-transit and out-of-transit data. Snowflake has been given FedRAMP Moderate approval.
Google Bigquery
Google claims that its data warehouses are always available and that all business intelligence tools deliver query response speeds in under a second. For the purpose of providing real-time analytics, Google BigQuery's technology is designed to run at petabyte speed and with huge concurrency.
Microsoft Azure Synapse Analytics
Data ingestion from more than 95 native connections is supported by Microsoft Azure Synapse Analytics' code-free visual ETL/ELT operations. T-SQL, Python, Scala, Spark SQL, and .NET are supported for both serverless and dedicated resources in Azure Synapse Analytics, which enables use cases for data lakes and data warehouses.
Conclusion
According to the website “Valuates Reports” the market for data warehousing, which was valued at $21.18 billion in 2019, is expected to grow to $51.18 billion by 2028.
The data warehouse concept is wide and could take you months to understand the whole concept around it, that's why I would recomend watching this data warehousing course and also reading this Kimball’s Data Warehouse Guide, which would help you learn the core and important concept in your data warehousing journey.
If you have any questions, don't hesitate to contact me on twitter :).